When developing in FileMaker, your default option for key values is FileMaker's auto-enter serial numbers. While this option can use an alphanumeric value instead of strict serial numbers, the general consensus for these documented standards is to use a universally unique identifier (UUID). Using a UUID scheme for creating keys nearly eliminates the chance of creating duplicate keys, which is a common problem when migrating data to new files (and remembering to reset auto-enter serial numbers) and when merging data created on multiple devices.
Warning about duplicates
By default, the native FileMaker environment provides the Duplicate Record option within the Records menu. If one of the goals in using a UUID is to eliminate the possibility of duplicates, then a few extra steps will be required. See the best practice section below.
Best Practice
It is suggested that a wrapper custom function be used when integrating UUID values. A wrapper function is simply a Custom Function with a unique name which points to another chunk of code, internal or external function - see method stub. The suggested standard name for this reserved function is UniqueID.
In FileMaker, UUIDs are generated using one of three ways: FileMaker's Get ( UUID ) function, plug-ins, or custom functions. Any one of the methods below may be referenced within the UniqueID custom function. When using a UUID for your key value you may also want to follow the settings in the following dialogs.
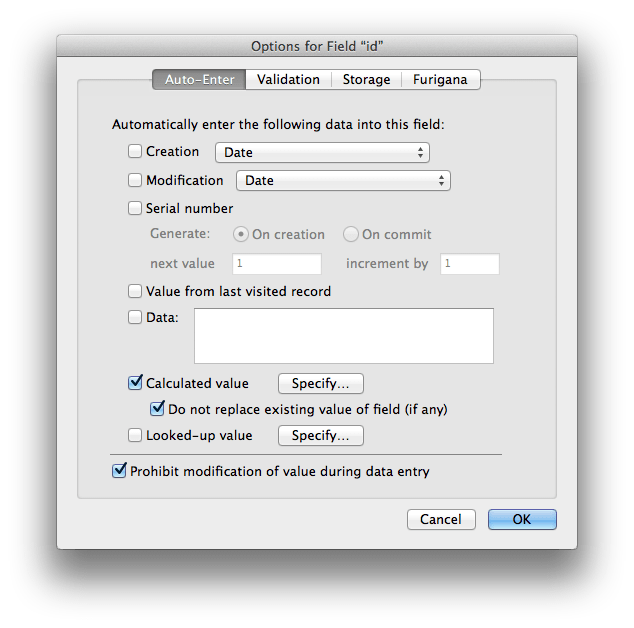
In the above image the Calculated value is using the suggested UniqueID custom function. The option of "Do not replace..." is checked to prevent the replacement of the original value used. The "Prohibit modification..." option is set to prevent any accidental changes to the key value (should it be exposed to the end user - which is not suggested).
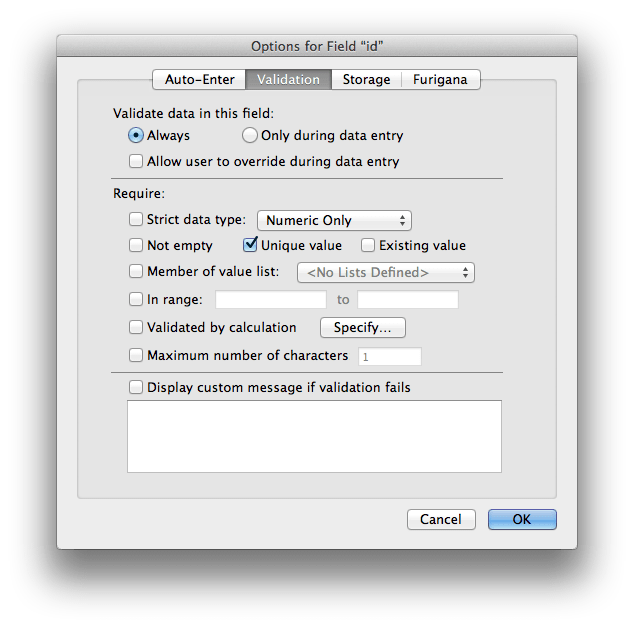
The validation options for the id key field have been set to require a "Unique value" and to ALWAYS validate by unchecking the "Allow user to override..." and changing the default setting of "Only during data entry". Leaving the "Not empty" option unchecked is optional as the auto-enter nature of the field implies that a value will be inserted (even when using ODBC). By setting these options, any action, either by the user or via scripted alteration, if a duplicate key is used, the file will prompt for record reversion. This type of setup compels the solution developer to ensure the uniqueness and canonical state of the key field. Features, such as the OnObjectValidate script trigger and using File > Manage > Custom Menus... (e.g. removing the Duplicate Record menu item) are methods one can employ to achieve the desired goal.
Supporting Record Duplication
By far, the most ensured way of avoiding any possible duplicate ID values is to use the settings above. Of course, FileMaker's validation will always catch any duplicates based on the "Unique value" validation. The method of supporting the creation of duplicate records, or cloning, is typically best handled via an OnRecordCommit layout trigger and through the use of a scripted process.
It is ALWAYS suggested that record cloning be managed via a script within the user interface. However, using a script trigger is inherently tied into the user interface and is layout or object specific. If a lower level method of duplication support is required then the following modifications may accomodate this.
In order to support FileMaker's native record duplication feature with UUIDs, just one change to the above dialog boxes must be made. The "Do not replace existing value of field (if any)" checkbox must be unchecked.
So long as no other fields are reference by this calculation, it should only generate a new UniqueID when a new record is created or duplicated. With the "Prohibit modification of value during data entry" checked, the user cannot modify the field value even if the ID field is shown and accessible (which, in most all cases, it should not be).
UUID Options
Get ( UUID )
In version 12, FileMaker introduced the Get ( UUID ) function, which creates a unique 36-character string of mostly random hexadecimal digits according to the RFC 4122 standard. For example:
03E1BB14-B04C-4ACF-A1ED-C90E59EE0396
Plug-in based UUIDs
ScriptMaster by 360Works
The ScriptMaster plug-in by 360Works can call on Java standard libraries to generate UUIDs. The demo file included with ScriptMaster contains an example generating a random (version 4) RFC 4122 UUID, which looks like this:
4bf08957-6c8e-465a-946c-aa7b36d831cd
Custom Function based UUIDs
Custom functions for creating UUIDs are more portable than plug-in based UUIDs. Though you do need FileMaker Pro Advanced to install custom functions in a file, well-designed functions will execute correctly in all FileMaker platforms without the need to distribute and install a plug-in, to create a server-compatible version of a plug-in, or even the ability to run a plug-in in the case of FileMaker Go.
For security reasons Apple removed the ability for iOS apps, including FileMaker Go, to access the device NIC address in iOS 7. FileMaker Go running on iOS 7 will simply return "02:00:00:00:00:00" for the NIC address, regardless of the actual NIC address. Historically, some FileMaker UUID functions used Get ( SystemNICAddress ) as a component of generated UUID values, but this leads to a significant risk of different devices creating duplicate values at the same time, so any UUID functions using Get ( SystemNICAddress ) are now strongly discouraged. The Get ( PersistentID ) function introduced in FileMaker 12 is an acceptable substitute.
Tom Robinson's UUID ( Type ) function
Tom Robinson's UUID ( Type ) function creates hexadecimal UUIDs consistent with the international standard scheme. By passing the function different parameters, you can generate version 1 UUIDs (encoding timestamp and NIC address) or version 4 UUIDs (encoding random numbers). A sample (version 4) UUID looks like this:
f47ac10b-58cc-4372-a567-0e02b2c3d479
Calling this function with UUID ( 1 ) or UUID ( "1h" ) will attempt to use the Get ( SystemNICAddress ) function, which will not return a correct result in iOS 7 or later, potentially leading to duplicate values. So using this function to generate type 1 UUIDs is strongly discouraged.
Jeremy Bante's UUID function
The UUIDTimeDevice function by Jeremy Bante (maintained in the fmpstandards Github repository) encodes the creation timestamp (UTC), part of the device's persistent ID, and a self-managed serial number. The generated values can be stored in a number field, which has certain performance benefits, and are meaningfully sortable by creation timestamp. Related functions are available for extracting the encoded timestamp, and for converting values to the conventional hexadecimal representation. A value from UUID looks like this:
12063524304235234000007854171467283736889
For situations where the privacy of a device persistent ID or a record creation timestamp is a concern, there is a related UUIDRandom function, which generates values like this:
42141279241146726753204187162615025729536
42 Comments
Matt Petrowsky
Nice list Jeremy! I like having these all in one place (so will other people). One thing we might want to consider is a recommendations section or a preferred method. Since you use your own, and I've been working with a ScriptMaster based plug-in for my Theme Studio, we don't have a "Editor's Choice" per se.
Not to say that we have to have one, but it may benefit others. Over time, others may comment here about pros and cons about the different methods.
I'll add in the plugin and AS based options.
Jeremy Bante
Thank you. I've had UUID variations on the brain recently for a pet project.
It occurred to me while writing the custom functions' introduction that we're listing several options for different ways to accomplish the same thing rather than saying, "There are other good ways, but we do it this way around here," like a good standard should. I agree that having at least a preferred scheme would make these standards more effective.
I'm personally reluctant to participate in picking one because I have an obvious bias, and I don't want to hurt the credibility of the choice. I'm hoping a natural winner will percolate in due time once we've gathered the shortlist of contenders in one place.
Arnold Kegebein
I agree with Jeremy's argument about picking a specific UUID function. Also, besides personal favors, the developer has to consider requirements and restrictions from the client and third parties. For example, some countries (e.g. Germany) have strict rules about data privacy. Under certain conditions it would not advisable to use a UUID that is based on a NIC, because it would allow to trace the record back to the user.
Still, I think it is reasonable to use one specific custom function name (e.g. UUID) for any sample code and example database. In the worst case, a developer can create this function to redirect to the actual function, the same way you should encapsulate plug-in functions.
Matt Petrowsky
I agree with standardizing on the name and I'm cool with UUID it can be used as the actual function or as a wrapper - which is more flexible. I'll put UUID as a reserved custom function name in the Reserved elements section.
Jeremy Bante
I ran some performance tests this morning on a new variation of my UUID function, and I was surprised by the results for ScriptMaster's performance. I was expecting ScriptMaster to be faster than all of the custom function methods for generating UUIDs. Here are the results from one test I ran:
Seconds to create 5000 UUIDs
My other calculation speed tests on a Mac are at least as bad. In one test, ScriptMaster took more than 10 times as long as the slowest custom function to generate the same number of UUIDs. My test on Windows wasn't as bad, but ScriptMaster was still slower than the slowest custom function.
But there's more to performance than creation speed. The UUID generated by ScriptMaster is formally the same as Tom Robinson's functions, so I didn't bother re-running these tests:
File size with 100k records
Seconds to perform 2500 finds
I ran other tests on Count() and Go to Related Record performance that found no meaningful differences.
Anonymous
Worth noting a gotcha that Auto Enter Calculation UIDs Custom Functions (plugins should be ok) above will produce duplicate ID's if user has access to Filemaker's native 'Duplicate Record' function and the "Do not replace existing value of field (if any)" checkbox is checked in UID fields 'auto enter' options.
The fix is to uncheck the option or script & secure menus around it. I've used unchecked option with Rays CF for few years and not run into issues to date although can't say I've robustly tested (ie. not turned any clocks back, tested in sync systems etc)
Interested to hear if any risks in simply unchecking the 'Do Not Replace..' option or if someone has delved deeply into Filemakers data level triggers, would love to hear more. ie. is it safe if auto enter referenced objects are wrapped within CF at creation point rather than directly referencing the filemaker objects directly in the Auto Enter UID field?
Rgds
Olly
Anonymous
Just because I don't know where else to be a smart a$$.... ;-)
I just looked at Jeremy's UUID function here
Very nice implementation, makes instant sense just looking at the code. I do think there is a superfluous "g" in this statement, though:
$~nicDigit = Position ( "0123456789abcdefg" ; $~nicDigit ; 1 ; 1 ) - 1; //convert digit to number
Unless the function covers the heptadecimal system as well, of course... :-P
BTW, I am a relative FileMaker newbie and I really appreciate you guys taking the time to document these best practices here. Coming from a more traditional professional software development / maintenance / deployment background, getting some structure laid out for me for how to use FileMaker is extremely helpful. It still feels like FM is geared towards the non-engineer and some essential features present in professional IDE's are still lacking. But it does have A LOT of things not found elsewhere that significantly increase productivity. Anyway, just wanted to voice my appreciation for your work here and elsewhere!
Stefan
forums [at] sievert-online dot net
Anonymous
Hi all,
for what it's worth, I posted my own function here : http://www.fmfunctions.com/fname/uid
I think it cannot be as fast as Jeremy's, but it's reasonably fast (8 secs to create 5000 records on my machine, without freeze window), and much faster than function using word separators (dash, blank...) during find operations.
And it's almost human readable, which is not bad during development.
Anonymous
This is great - thanks guys...
2 questions on Jeremy's version:
1) I see that you say that it "can" be a number, but do you recommend making the pK field a Text or Number field.
2) "related" to the above, if you are building a relation to a multi-line key, will the pure number version on one side of a relation match with a multi-line key (text) version on the other?
And in general on this topic, our users are used to seeing some sort of memorizable record number on their screens. When switching to a UUID method, do you still typically have a "simple" (non-key) serial number counting away on screen for reference?
Thanks!
Joel Stoner
Jeremy Bante
To get the more important performance benefits of my version (file size and find speed), the UUID needs to be stored in a number field — it's the primary reason I made my version of the function.
I just ran a test, and a text-based multi-line key will match with a numeric primary key field.
Whether or not I create another human-readable (and not just developer-readable) ID depends on the context. Contact records tend to have name fields that work reasonably well without an ID, but Invoices usually need readable invoice numbers, and I do make a separate field for that.
Matt Petrowsky
..and yet a good reason to also use an incrementing serial value for contacts is if you're using bar codes. A UUID for a bar code makes for a pretty large ID Badge
Anonymous
Wow you're fast Jeremy...
Another thought... in the older "serial number" paradigm, it was important to validate the field as Unique. I'm wondering that since a UUID is infinitely more likely to be unique from the get go, even when importing other data sets, if having this Unique validation is as required as it used to be, and what kind of speed hit validation has?
I know I could test this myself, but I'm more curious of your thoughts on: if requiring UUIDs to be unique is excessive. Of course one could come up with cases where it makes sense to have it on, but in general, maybe it's reasonable to leave off?
Thanks again...
Jeremy Bante
I tend to leave validation for uniqueness on anyway; there's nothing wrong with wearing a belt with suspenders (especially if they match). There is a performance hit, but I never found it to be a big deal unless you're creating hundreds of thousands of records at a time on a regular basis.
Anonymous
Just came across something important to know about using Jeremy's UUID: Because it contains the @ character, which is also an operator in FileMaker finds, you can't do a scripted (or manual) find for one of these IDs. In find mode, FileMaker interprets it as a "any one character" operator and the returns no records.
Anonymous
(I posted the above...)
I swapped the @ for an underscore _ and that restored Find functionality...
Joel Stoner
Jeremy Bante
Thanks for catching that, Joel. I haven't had this problem in my own use of the function, but I just posted a fix for it to Matt's branch of the GitHub repo, along with some internal variable name updates.
Matt Petrowsky
I've pushed the fixes into the master github repo.
For those who are collaborating on custom functions and using pull requests, make sure to work off the working branch that I have at my personal github repo for fmpfunctions. This is a place where we can review and discuss functions before pushing into the fmpstandards master.
In fact, you'll find a lot more functions there than the master because that's where I'm adding mine first. Some of them will lack documentation.
Anonymous
Are you able to tell us how you had that happen? I've got tons of stuff searching on the UUID and I've not had that happen. Would like to know how to replicate so it doesn't happen..
Russell Barlow
Anonymous
Hi Jeremy, Matt and all, with implementing the UUID I am considering how to then create the unique readable invoice numbers. I do need to have readable invoice numbers, but how to keep them unique when I have mobile users syncing with the host file. Would you just have the host assign a new invoice no. when uploading the records to host, as in a serial id? Or use another form of Invoice number concatenating the account id with a record id? When I consider this it seems the UUID is almost redundant in that I now will have two unique id's. I would appreciate your thoughts on this and how you approach this situation. Jeremy specifically where you state "and I do make a separate field for that". What is your method?
Thanks,
Ben Graham
Jeremy Bante
In these situations, I'd do as you describe. The invoice record has an internal UUID for its primary key, then the server runs a regular schedule adding invoice numbers to newly-uploaded invoices. Having both isn't entirely redundant, since the UUID is internal to the database, whereas the invoice number is a semantic key. Consider this: customer addresses are typically unique to customers, so the customer ID is redundant with the customer address; but we keep both pieces of data because they're useful for the needs of different systems, such as the database internals and the post office. Similarly, the UUID for an invoice is a useful internal key, whereas the invoice number is more useful for communicating with the customer.
Anonymous
Any find using a paste or a insert text will fail because of the reserved character. Frankly, I'm surprised it ever works under any circumstances. I guess there are times when the fact that is a reserved character doesn't come into play. --Jonathan Fletcher
Anonymous
I'm having a problem when using the GetLayoutObjectAttribute ( ) function. I'm trying to gather a list of IDs on the layout side of a filtered portal. So I gave the id field an object name and used
GetLayoutObjectAttribute ( "idField" ; "content" ; 1 ; 1 ) in a recursive function. What it returned was:
1.2063e+40
1.2063e+40
Instead of:
1-2-063466124131-0000000-08714-233916158973329
1-2-063466119277-0000000-08714-233916158973329
I wanted to use PaternCount ( ) to compare an id in a global field and see if it was in the list of IDs from the portal. But I can't seem to get the values properly.
Jeremy Bante
The result you're getting is the UUID expressed as a number in scientific notation, which is how FileMaker displays very large and very small numbers in the default "General" number format for a field on a layout. If you edit the idField object in layout mode to use the "As entered" number format (Inspector palette > "Data" tab > "Data Formatting" section), you should be able to get the full UUID.
Anonymous
I thought I had tried that. But I went back and did it again and it worked fine.
Thanks
Anonymous
Something else i've run into. When i set the IDs to variables it seems like sometimes it has the dashes and sometimes it doesn't. I'm really not sure why. But then when I use something like PaternCount () to compare a list of IDs to a variable I have to substitute out the dashes to be sure to get a match.
Anonymous
And still more problems with the UUID. From one layout I have a relationship to another table based on a global field. To create a record I clear the clobal and set fields through the relationship in the related table causing a new record to be created ( Sometimes called the magic key technique ). If I put the related fields on the current layout and manually enter a value into a field it causes a record to be created and the id of the new record is set to the related global key field. My problem is, when I perform the same action using a script the id of the new record fails unique validation. When I turn off unique validation and check a newly created record by doing a find for "!" in the id field it does indeed turn out to have a duplicate id. This does not happen when i enter directly into the fields but does when I use a script to do the exact same thing.
Home » Employees ( zmagickey ) |-------| Home » Attributes Create ( id )
Set Field [ Home » Employees::zmagickey; "" ]
Set Field [ Home » Attributes Create::id_fkey; Home » Employees::id ]
Set Field [ Home » Attributes Create::type; $type ]
Commit Records/Requests
When I write a traditional script that grabs the Employee id, goes to the attributes layout, create new record and so on, it does not have this problem. Nor does the problem occure when using a portal with allow record creation in the usual way.
So what gives?
Jeremy Bante
I haven't heard of this before. I'd like to test it myself when I get a chance, but in the mean time, can you tell us exactly which UUID function you're using?
Anonymous
I downloaded the standards.fp7 file a couple weeks ago and I imported the function from there.
From the documentation
https://github.com/petrowsky/fmpstandards/blob/master/Functions/UUIDNew.fmfn
RELEASE: 2011-02-23
UUIDNew: http://www.briandunning.com/cf/1220
Jeremy Bante
I've noticed this, too. I suspect that it happens because the value is treated as a number in some contexts and as text in others. The hyphens would be removed when the value is treated as a number. Since the hyphens are only there as a visual aid and all the information content is in the digits, you could remove the inconvenience of having to substitute out hyphens by removing them from the UUID functions themselves.
Anonymous
Hello Jeremy!
I saw there is a new Get(UUID) function in FM12. I would be interessed in hearing your opinion about the FM12 UUID. There is not much information in the FM12 help about what kind of UUID it is, except that it's a 16-Byte (128-Bit) hexadecimal UUID.
Example:
E47E7AE0-5CF0-FF45-B3AD-C12B3E765CD5
Are they consistent with the international standard scheme (random UUIDs version 4)?
It should be slower in finds, since it's not a number ... that's clear. But perhaps it will become the new standard, because now it's built into FM. But it doesn't has the benefits of a timestamp or NIC address (which also can be a minus point of course).
Thanks,
Patrick Horn
Jeremy Bante
The new Get ( UUID ) function in FileMaker 12 does indeed create values according to the version 4 (random) RFC 4122 specification. (The value you provided does not fit the standard. The first digit in the 3rd group should be "4," indicating the version number.) This doesn't have the information content of a version 1 (timestamp & NIC address) UUID or any of the similarly inspired solutions the FileMaker community has developed, but that can be a good thing for theoretical, privacy and, in some countries, legal reasons.
I ran some tests comparing the performance of the various solutions to Get ( UUID ). I found that:
Converting Get ( UUID ) to a decimal number is relatively slow, but the result is a couple digits shorter than my own UUID functions generate, and is therefore a little better for find speed and file size. I still want to test the speed of calculating a decimal random RFC 4122 UUID directly, rather than converting from Get ( UUID ). If random is the way the wind is blowing, there isn't any value in sticking to the structured format from my version 1 UUIDs.
Anonymous
Hello Jeremy!
Thanks for fast answering and the informations.
One comment: I found the example for the FM12 UUID in the help of FM 12 Advanced (german language). Strange that the first digit in the 3rd group isn't a "4".
I also searched in the knowledge base of Filemaker (for "UUID"), but did not found useful information, except that it's perhaps also worth to take a look to the new function Get(PersistentID) to create UUIDs? (But also again with the restrictions of data privacy and laws in certain countries – here in Germany we are quite sensible about this, I think.)
But wouldn't it be a good way to use the FM12 UUID as a basis and convert it to a decimal number if finding speed is an issue? I'm not sure if there are many scenarios where the creation speed (converting-to-number speed) is important – my experiences are limited in this point.
Have a nice day!
Patrick
Jeremy Bante
Now that FileMaker has a native Get ( UUID ) function, do we want to fall in line and adopt it? If performance of number fields is important enough for us to say "not necessarily," do we want to play nice with the RFC 4122 standard and promote using an exact decimal equivalent, or are the ones I developed close enough? (There's a one-to-one correspondence between what I built and RFC 4122, but it's not exactly the same format.) We never got around to revising the best practice to say, "There are many UUIDs, but we like this one." Is it time to pick one?
Matt Petrowsky
My inclination, and I'm assuming yours might be too, is to err on the side of convenience.
If it's there then just use it - which would mean Get ( UUID ). I know there may be some ego included in your versions (because, simply, they are cool - and I'm not saying you "have" an ego (as in "I'm a big shot") - just that we all must admit that we take pride in what we produce)
As far as suggested spec, I would like to see us promote the use of a wrapper custom function of simply UUID(). This provides the greatest degree of flexibility. It can reference Get ( UUID ) or use any other variation.
If there is a reason that any of the others are used, such as for integrated timestamp, etc, then the CF provides a great place to make notes about such a decision.
If I opened a solution and saw UUID(), I would know it's following our suggested standards and I would be able to confirm what variation is being used.
How does that sound?
Jeremy Bante
I like it, except for the particular name of the function. Now that "UUID" is a flag for a Get() function, it's not accepted as a custom function name in FileMaker 12. Any other suggestions? UUIDNew? GetUUID?
Perren Smith
I'd go with GetUUID. I've done that with other CFs when I'm bumping into the FileMaker namespace...
Matt Petrowsky
I tried the "Get" prefix for a short time, but I've abandoned it personally. I didn't want to introduce visual confusion - despite the fact that you can clearly see the lack of a "(".
Initially my thought was UUID4, but, wouldn't want to scope it to the implementation.
What about just chopping off a "U"?
UID()
That's pretty simple and we'd know what it does. It also has the slight advantage (or disadvantage depending on perspective) of breaking away from UUID - yet is still related.
Perren Smith
We know what it does, but UID is used in Open Directory / Workgroup Manager as "User ID"...that could confuse the system administration camp.
How about UniqueID? A bit longer to type, but it clearly conveys what the user would be getting as the function result.
Jeremy Bante
I like UniqueID.
Matt Petrowsky
Yep, I think that is pretty clear. Let's ratify.
Anonymous
I agree with all of the above. Nice job, guys.
Jeremy, I use your CFs all the time and they're great, but I'm with Matt, the convenience factor has a lot to offer. Add to that the fact that FMI has now thrown their hat into the ring on a "standard."
Jonathan Fletcher
Anonymous
Well, I'm still disappointed that the new Get(UUID) does not match the "Values stored in number fields still outperform values stored in text fields for find speed and file size, hands down." I'm inclined to stick with Jeremy's UUID numbers since we have to live with find speeds and file sizes from day to day and minute by minute.
The terrible irony of Get(UUID) is that it really is returning a number (a hexadecimal number), but it's coming out as costly text just to store 6 alphabetic characters. There ought to be a no-cost means of storing hexadecimals in number fields, just as there is a no-cost means of storing decimals in number fields.
Eric Matthews